



多模态大模型幻觉降低30%!中科大等提出首个幻觉修正架构「Woodpecker」啄木鸟
英文: Tesla Offers $48/Hour to Train Optimus Robots with Motion Capture
新智元报道编辑:好困【新智元导读】最近,来自中科大等机构的研究人员提出了首个多模态修正架构「啄木鸟」,可有效解决MLLM输出幻觉的问题。视觉幻觉是常见于多模态大语言模型(Multimodal Large Language Models, MLLMs)的一个典型问题

新智元报道
编辑:好困
【新智元导读】最近,来自中科大等机构的研究人员提出了首个多模态修正架构「啄木鸟」,可有效解决MLLM输出幻觉的问题。
视觉幻觉是常见于多模态大语言模型(Multimodal Large Language Models, MLLMs)的一个典型问题。
简单来说就是:模型输出的描述与图片内容不相符。
下图中体现了两种幻觉,红色部分错误地描述了狗的颜色(属性幻觉),蓝色部分描述了图中实际不存在的事物(目标幻觉)。

幻觉对模型的可靠性产生了显著的负面影响,因此引起了许多研究者的重视。
以往的方法主要集中在MLLM本身,通过在训练数据以及架构上进行改进,以重新微调的方式训练一个新的MLLM。
然而,这种方式会造成较大的数据构建和训练开销,且较难推广到各种已有的MLLMs。
近日,来自中科大等机构的研究者们提出了一种免训练的即插即用的通用架构「啄木鸟(Woodpecker)」,通过修正的方式解决MLLM输出幻觉的问题。

论文地址: https://arxiv.org/pdf/2310.16045.pdf
项目地址: https://github.com/BradyFU/Woodpecker
效果展示
具体来说,Woodpecker可以修正各种场景下模型输出的幻觉,并输出检测框作为引证,表明相应的目标确实存在。
例如,面对描述任务,Woodpecker可以修正其中带有幻觉的部分:

对于MLLM难以检测到的小对象,Woodpecker也可以精准修正:

面对MLLM难以解决的复杂的计数场景,Woodpecker同样可以进行解决:

对于目标属性类的幻觉问题,Woopecker处理地也很好:

此外,Woodpecker还提供了Demo供读者测试使用。
如下图所示,上传图片并输入请求,就可以得到修正前以及修正后的模型答复,以及供参考验证的新图片。

方法
Woodpecker的架构如下,它包括五个主要步骤: 关键概念提取、问题构造、视觉知识检验、视觉断言生成以及幻觉修正。

- 关键概念提取
关键概念指的是MLLM的输出中最可能存在幻觉的存在性目标,例如上图描述中的「自行车;垃圾桶;人」。
我们可以Prompt大语言模型来提取出这些关键概念,这些关键概念是后续步骤进行的基础。
- 问题构造
围绕着前一步提取出的关键概念,Prompt大语言模型来提出一些有助于检验图片描述真伪的问题,如「图中有几辆自行车?」、「垃圾桶边上的是什么?」等等。
- 视觉知识检验
使用视觉基础模型对提出的问题进行检验,获得与图片以及描述文本相关的信息。
例如,我们可以利用GroundingDINO来进行目标检测,确定关键目标是否存在以及关键目标的数量。因为像GroundingDINO这类视觉基础模型对图片的感知能力比MLLM本身的感知能力更强。
对于目标颜色等这类属性问题,则可以利用BLIP-2来进行回答。BLIP-2这类传统VQA模型输出答案的长度有限,幻觉问题也更少。
- 视觉断言生成
基于前两步中获得的问题以及对应的视觉信息,合成结构化的「视觉断言」。这些视觉断言可以看做与原有MLLM的回答以及输入图片相关的视觉知识库。
- 幻觉修正
基于前面得到的,使用大语言模型对MLLM的文本输出进行逐一修正,并提供目标对应的检测框信息作为视觉检验的参照。
实验结果
实验选取了几个典型的MLLM作为基线,包括: LLaVA,mPLUG-Owl,Otter,MiniGPT-4。
论文中首先测试了Woodpecker在面对目标幻觉时的修正能力,在POPE验证集的实验结果如下表所示:

结果表明在不同的MLLM上应用Woodpecker修正后,均有不同程度的提升。
在随机设定下,Woodpecker给MiniGPT-4和mPLUG-Owl在准确率指标上分别带来了30.66%和24.33%的提升。
此外,研究者还应用更全面的验证集MME,进一步测试Woodpecker在面对属性幻觉时的修正能力,结果如下表所示:

从表中可见Woodpecker不仅在应对目标幻觉时有效,在修正颜色等属性幻觉时也具有出色的表现。LLaVA的颜色得分从78.33分大幅提升到155分!
经过Woodpecker修正后,四个基线模型在四个测试子集上的总分均超过500分,在总体感知能力上获得了显著提升。
为了更直接地衡量修正表现,更直接的方式是使用开放评测。
不同于以往将图片转译后送入纯文本GPT-4的做法,文章利用OpenAI最近开放的视觉接口,提出使用GPT-4(Vision)对修正前后的图片描述直接对下列两个维度进行打分:
- 准确度:模型的答复相对于图片内容是否准确
- 详细程度:模型答复的细节丰富度
在该实验条件下,实验结果如下表所示:
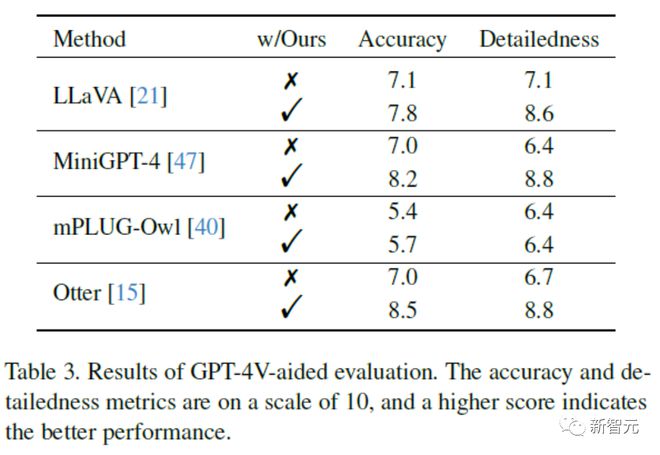
结果表明经过Woodpecker修正后图片描述的准确性有一定的提升,这说明该框架可以有效修正描述中幻视的部分。
另一方面,Woodpecker修正后引入的定位信息丰富了文本描述,提供了进一步的位置信息,从而提升了细节丰富度。
GPT-4V辅助的评测样例如下图所示:

感兴趣的读者,可以读论文进一步了解更多内容。
参考资料:
https://arxiv.org/pdf/2310.16045.pdf
https://github.com/BradyFU/Woodpecker
英文: Tesla Offers $48/Hour to Train Optimus Robots with Motion Capture
标签: 幻觉 模态 大模型 降低 中科大 提出 首个 修正 架构
声明:本文内容来源自网络,文字、图片等素材版权属于原作者,平台转载素材出于传递更多信息,文章内容仅供参考与学习,切勿作为商业目的使用。如果侵害了您的合法权益,请您及时与我们联系,我们会在第一时间进行处理!我们尊重版权,也致力于保护版权,站搜网感谢您的分享!

